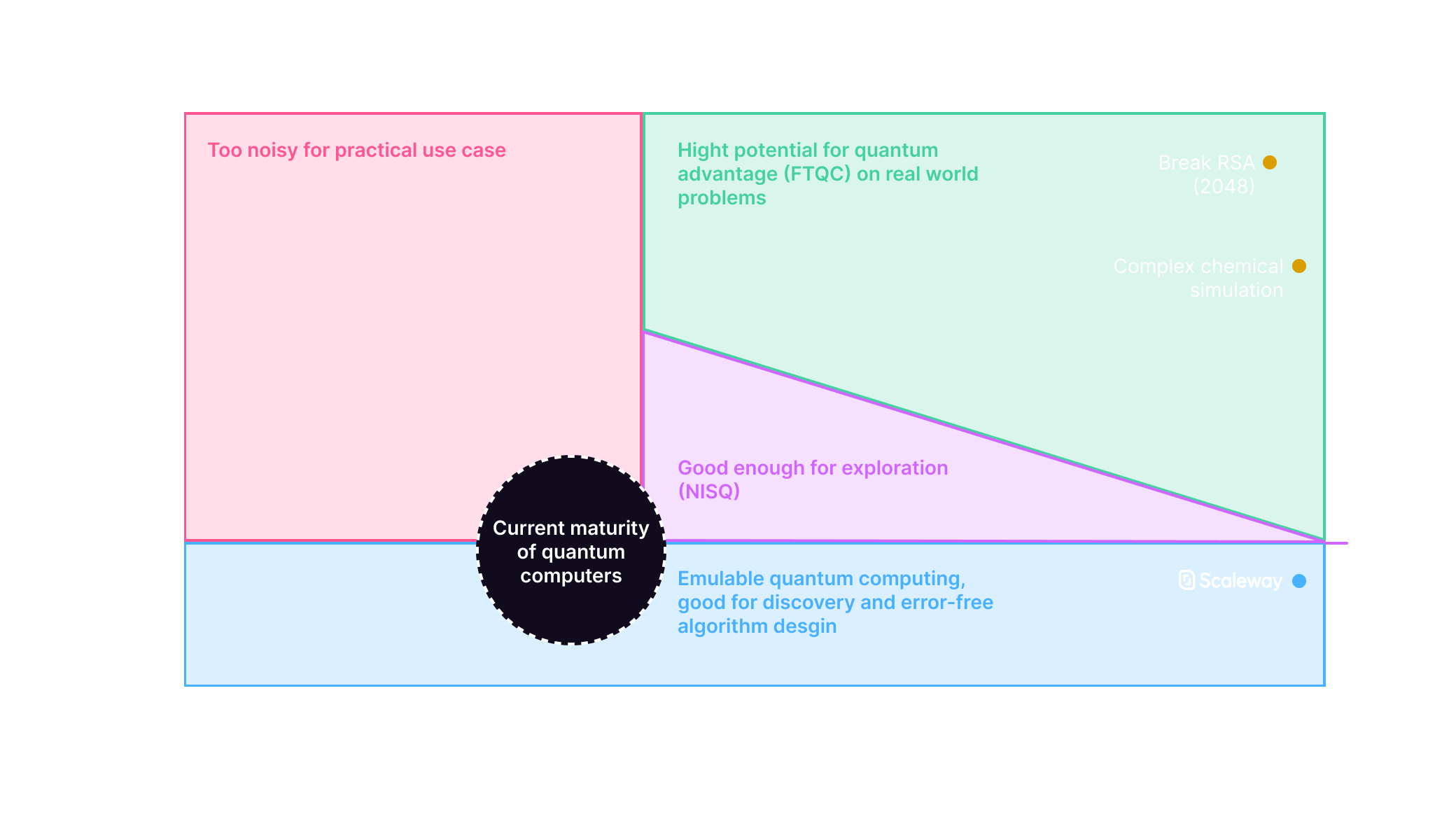
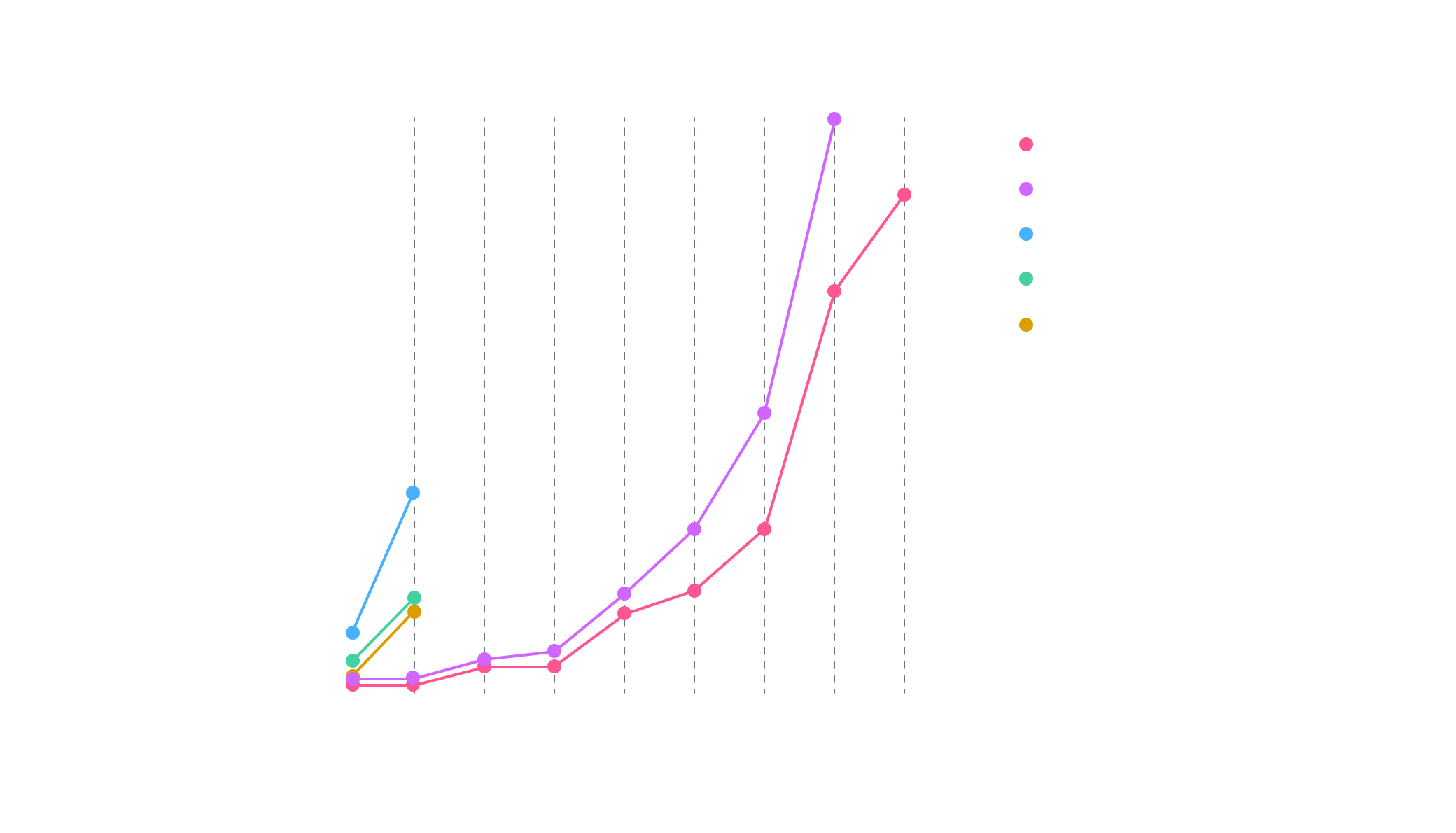
Quantum volume is a good tool to evaluate capacity of a platform. We run growing circuits until we reach hardware limitations.
We create square circuits, e.g. 24x24 or 30x30, denoting the number of qubits and the number of quantum gates (depth) respectively. These gates are randomly selected from Pauli X, Y, Z, Hadamar and 2-qubits control gates like CX and CZ. These squared-circuits, designed on Qiskit and Cirq SDKs, were executed on popular local setups and on our Quantum as a Service across different hosted platforms (always in state vector with double floating precision).
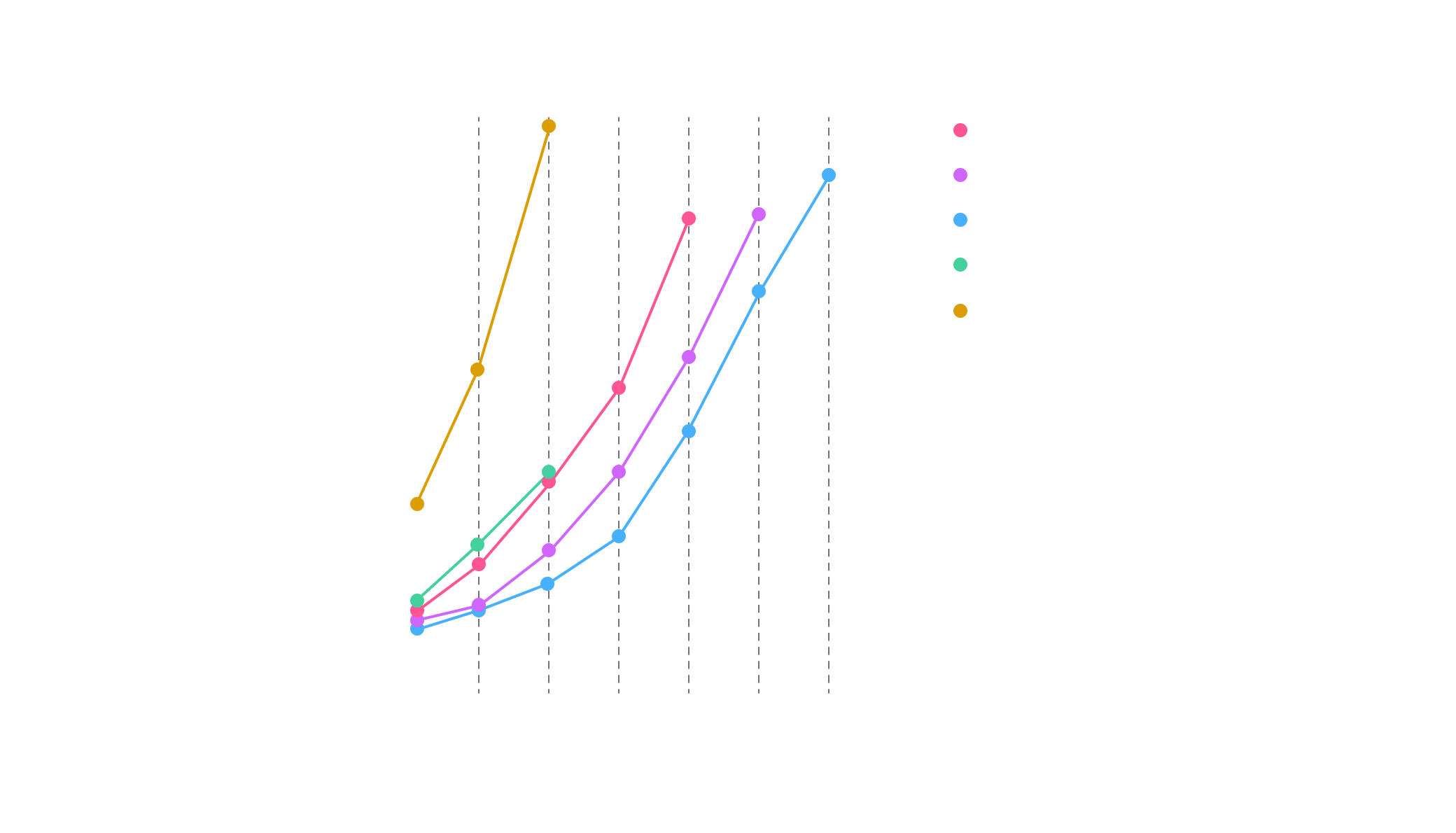
As you can notice in Figure 2, our CPU-based QaaS platforms ran from 2x to 10x faster than local setups on a few qubit count.
Moreover, in local setups we encounter limitations by running squared-circuits with more than 30 emulated qubits due to excessive memory requirement. In contrast, our 512GB memory platform enables us to extend up to 34 qubits in less time than a 30 qubits in local setup.
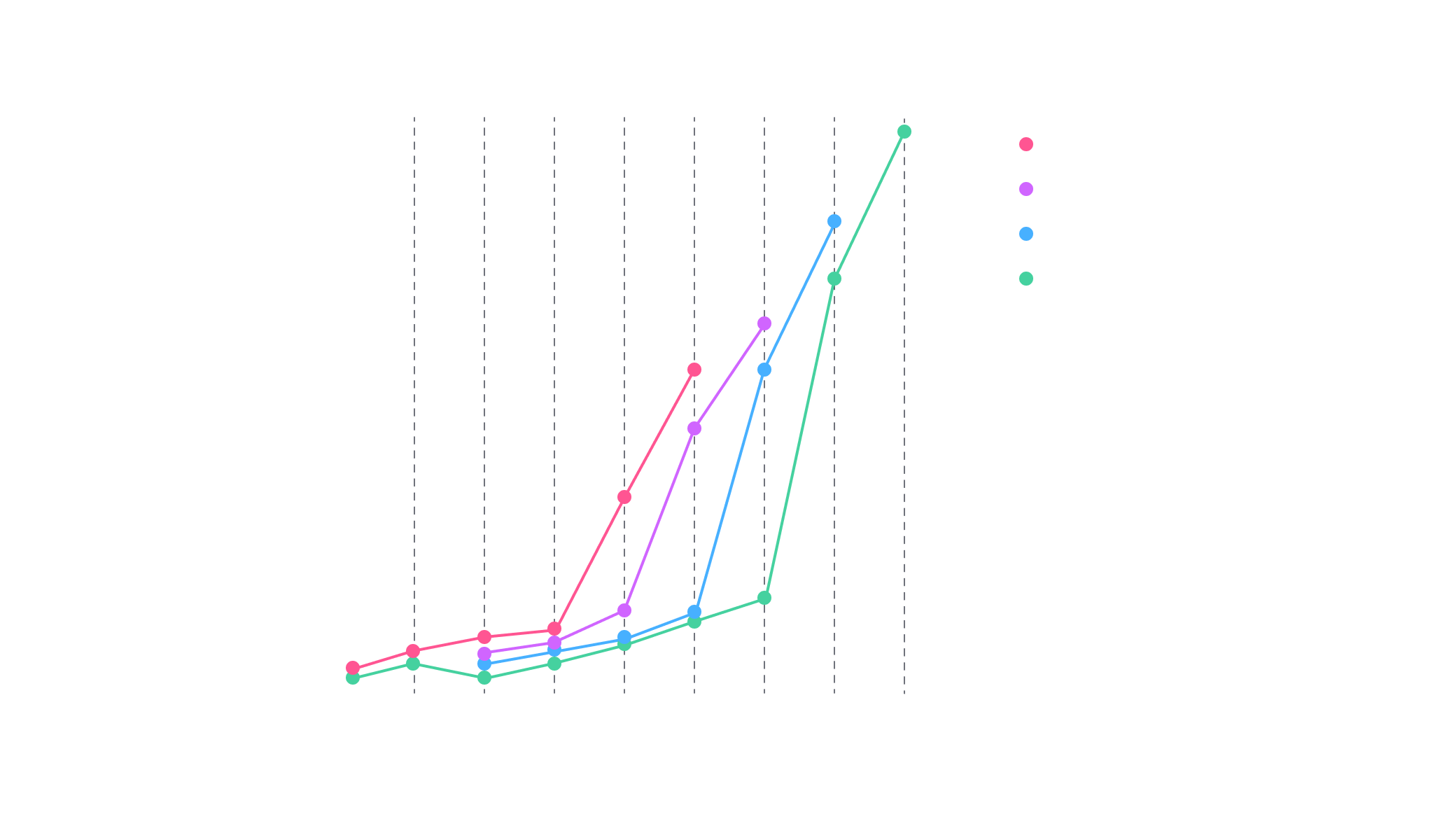
To go further, we also benchmarked our GPU-accelerated platforms. As depicted in Figure 3, it completely outperforms CPU-based platforms, a 34-qubits circuit passed from 150s on our C64512M to 12s on our 8-L80S configuration offering a 12x boost.
Moreover, these multi-GPUs platforms allow us to reach up to 36 qubits on squared-circuits, which is more than convenient to push forward quantum computing exploration. As our benchmark is double floating precision, it is possible to reach one additional qubit by switching to single floating precision.
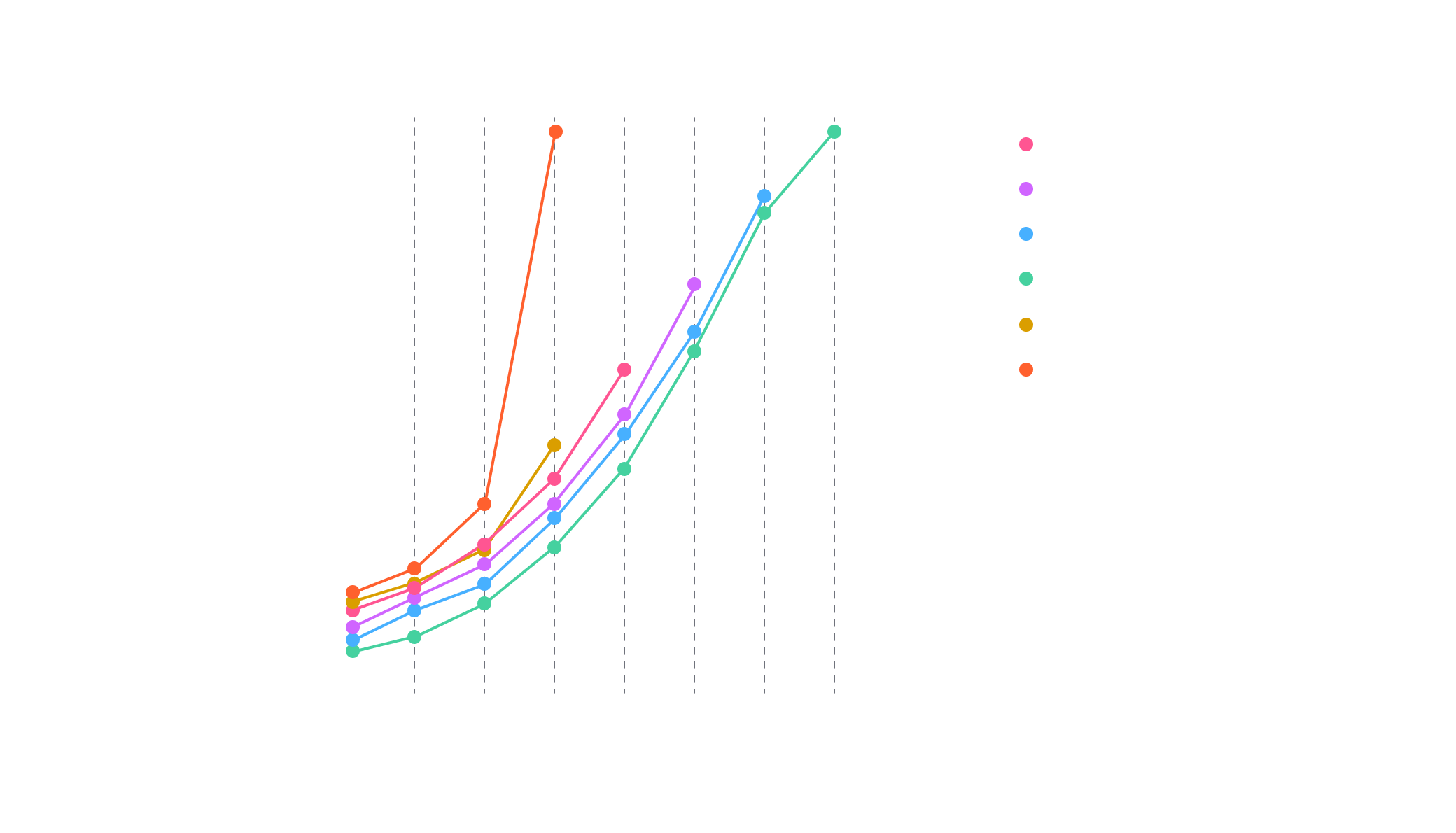
We also ran some benchmarks on Qsim emulation. Qsim is a full wave function simulator written in C++. It uses gate fusion, vectorized instructions and OpenMP multi-threading to achieve state of the art state vector simulations of quantum circuits. Figure 4 shows us really top performance on CPU setups. The average performance is twice time faster than Aer emulation and offers an additional qubit for the same hardware configuration.
For even faster Qsim execution, we provide GPU platforms powered by Nvidia cuQuantum.
When we run Quandela’s Exqalibur, which is dedicated to photonic emulation, we can notice that our GPU-accelerated platforms exhibit a substantial computation speedup for equivalent circuit size, taking less than a second compared to 241 seconds for Apple M2 or 695 seconds for an Intel i7.
Moreover, in local setups we encounter limitations by running squared-circuits with more than 11 photons due to excessive memory requirement. In contrast our H100 GPU-accelerated platform, enables us to extend up to 31 photons in 2h.